








近日,中国农业科学院北京畜牧兽医研究所微生物与酶工程创新团队和生物技术研究所微生物蛋白设计与智造创新团队合作,开发了基于预训练蛋白语言大模型的蛋白高表达预测与设计新策略,实现蛋白质语言大模型与基因表达深度融合,为高效创制高性能蛋白产品提供了新的思路与工具。相关研究成果发表在《先进科学(Advanced Science)》。
蛋白质的高效、可溶性异源表达是酶蛋白变成酶产品的关键核心环节。传统的策略包括更换表达宿主、表达载体或添加分子伴侣等,但这些策略很大程度上依赖研究人员的经验并且需要大量的实验验证,缺乏对蛋白质序列与其表达之间关系的认识。
本研究基于迁移学习理论,开发了国产化的预训练蛋白质语言模型MP-TRANS,该模型架构包含8层Transformer模块,总计拥有87,164,000个参数,预训练阶段高效利用了8张国产NPU计算卡。通过进一步对MP-TRANS模型进行下游任务的微调,构建了蛋白质表达量预测与分子设计平台。该平台包括88种不同宿主的表达量预测模型MPB-EXP,平均准确率为0.78,超越了传统机器学习技术,成为当前支持最多表达宿主的预测模型,可广泛适用于多类表达宿主。此外,本研究创新性地提出了氨基酸表达指数(AEI)概念,并据此开发了相对氨基酸偏好强度(SRAB)评估工具,为蛋白质表达提供了精确的量化工具。在此基础上,我们进一步开发了突变体生成模型MPB-MUT,通过智能重构目标蛋白序列,有效提升了其在特定宿主中的表达效率。最终,借助该平台,实现了木聚糖酶、纤维素酶及PET塑料降解酶在大肠杆菌中可溶性表达量的显著提升。
该研究得到国家重点研发计划、国家自然科学基金、中国农业科学院创新工程项目的资助。模型构建过程中,得到河北人工智能计算中心提供的计算资源支持。中国农业科学院北京畜牧兽医研究所田健研究员、黄火清研究员和中国农业科学院生物技术研究所关菲菲副研究员、刘波研究员为论文共同通讯作者,硕士研究生刘拓宇和张铱洋为论文共同第一作者。
原文地址:
https://onlinelibrary.wiley.com/doi/10.1002/advs.202407664
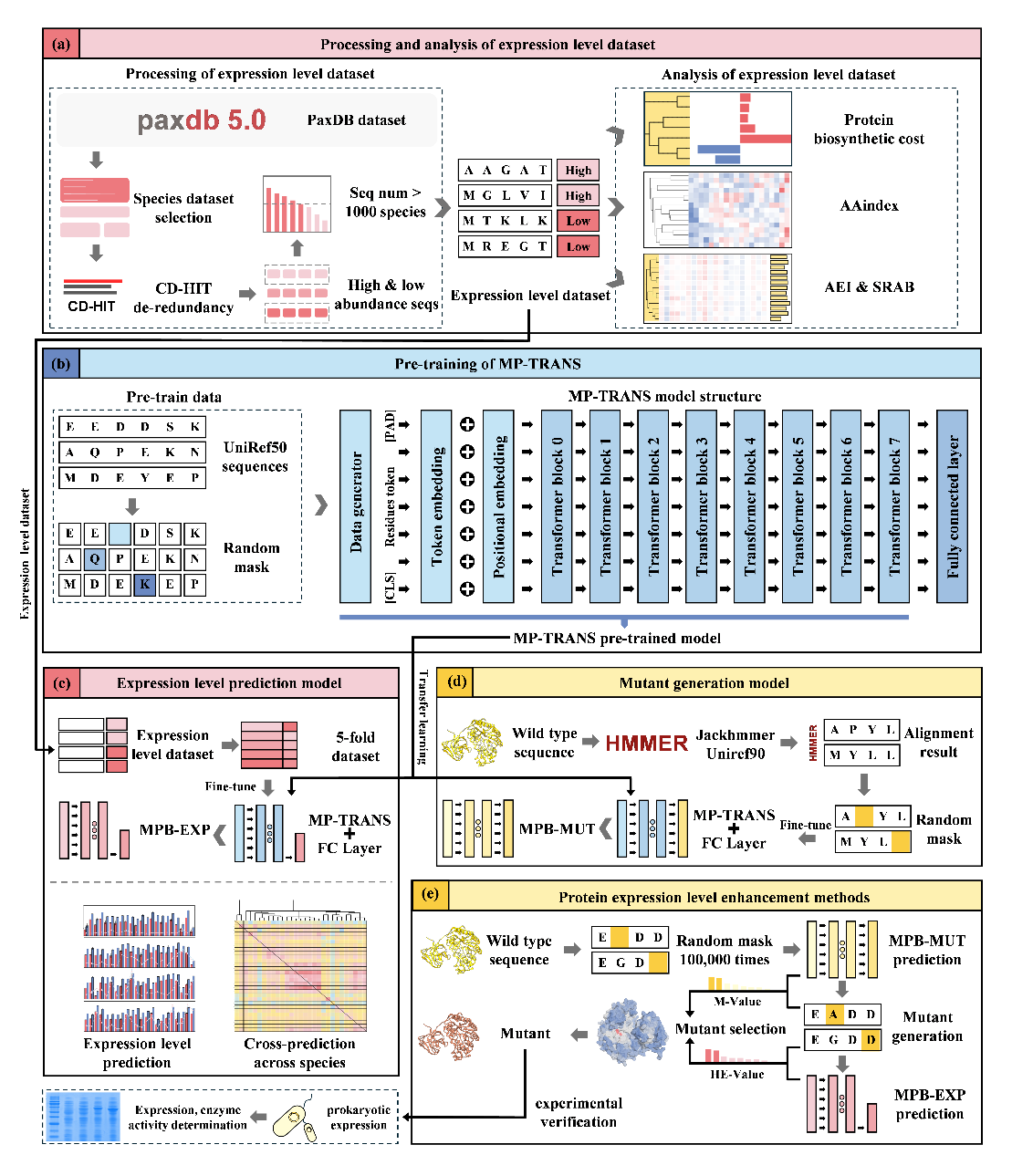
图 预测和生成突变体以增强蛋白质可溶性表达的工作框架